Adding Arrays to Rockstar
So, let’s add arrays to Rockstar. For the Advent of Code day 2, we specifically need to:
- Split a string into an array
- Read the value at a specific array index
- Write a value to a specific array index
So we’re going to need some new syntax, and probably a couple of new keywords. Now, paydirt in Rockstar is adding new language keywords that let you write genuine lines from real rock songs. So I take the idea of splitting something, come up with as many possible keywords as I can think of – split, shatter, tear, break, crack, cut, splinter – and see if any of those rings a lyrical bell:
Cut my life into pieces(Papa Roach - Last Resort)The seam is split / The coal face cracked(U2 - Red Hill Mining Town)Crack the big sky(Spock’s Beard)It's a fragment of love / From a splintering heart(Marillion)
Now, it occurred to me a while ago that because Rockstar allows variable names with spaces, it would actually be possible to create a completely unique function call syntax where the name of the function goes inside the variable name:
split(myArray)(C/C++ style)myArray.split()(C#/Java/JavaScript style)my split array(Rockstar midfix notation style)
But whilst that’s possible, it would involve some major changes to the variable name rules in the parser, so that’s maybe one to pick up for Rockstar 2.0. So I’m gonna go with the cut keyword (probably with a couple of aliases defined to make things a bit more flexible.)
For the array read/write syntax, we need some way of supplying an index to a lookup expression:
X is 1
Let my array at X be 2
Say my array at X
This also potentially extends to multidimensional arrays:
X is 1
Y is 2
Let my array at X, Y be 3
Say my array at X, Y
and even to jagged arrays:
X is 1
Y is 2
Let my array at X at Y be 4
Say my array at X at Y
The Grammar
OK, so we need to add three new rules to Rockstar’s grammer:
cut <variable> into <variable> with <delimiter>- lookups:
<variable> at <index> - assignment:
let <variable> at <index> be <variable>
Here’s the PEG rules that will enable the parser to recognise these new keywords. First, we’ll implement cut as a special case of assignment:
split = 'cut'i / 'split'i / 'shatter'i
assignment =
/* ... existing assignment rules ... */
/ split _ array:simple_expression _ 'with'i _ delimiter:expression _ 'into'i _ target:assignable
{ return { split: { array: array, delimiter: delimiter, target: target } } ; }
/ split _ array:simple_expression _ 'into'i _ target:assignable
{ return { split: { array: array, target: target } } ; }
Next, we need to extend the lookup rule to support the new <variable> at <index> syntax:
lookup
= v:variable _ 'at'i _ i:expression
{ return { lookup: { variable: v, index: i } }; }
/ v:variable
{ return { lookup: { variable: v } }; }
Finally, we need to be able to assign values to individual array elements. This is more complicated, because we need to introduce the notion of an assignable into our grammar - which can either be a scalar variable, or a combination of a variable and an index. And that’s gonna break the existing behaviour of the interpreter - but we’ll fix that when we get to it.
Here’s the grammar definition for assignables:
assignable
= v:variable _ 'at'i _ i:expression { return { variable: v, index: i }; }
/ v:variable { return { variable: v }; }
and here’s the grammar rule for assignments.
assignment = target:assignable is _* e:(literal / poetic_number)
{ return { assign: { target: target, expression: e} }; }
/ target:assignable _+ 'says 'i e:poetic_string
{ return { assign: { target: target, expression: e} }; }
/ 'put'i _+ e:expression _+ 'into'i _+ target:assignable
{ return { assign: { target: target, expression: e} }; }
/ 'let'i _+ target:assignable _+ 'be'i o:compoundable_operator e:expression {
return { assign: {
target: target,
expression: { binary: { op: o, lhs: { lookup: { variable: v } }, rhs: e } }
} };
}
/ 'let'i _+ target:assignable _+ 'be'i _+ e:expression
{ return { assign: { target: target, expression: e} }; }
/ split _ array:simple_expression _ 'with'i _ delimiter:expression _ 'into'i _ target:assignable
{ return { split: { array: array, delimiter: delimiter, target: target } } ; }
/ split _ array:simple_expression _ 'into'i _ target:assignable
{ return { split: { array: array, target: target } } ; }
Note that I’ve already added array split as a special case of assignment, so at this point I’ve had to decide whether you can put arrays into other arrays – in other words, am I going to allow this?
Split Array A into Array B at index
That should’t actually cause any additional complexity in the interpreter, so yeah, let’s try it.
OK, so now we have a working grammar for splitting strings and doing array lookups.
Next step is to plug in some test cases for it - here’s arrays.rock
Let my array at 0 be "foo"
Let my array at 1 be "bar"
Let my array at 2 be "baz"
Shout my array at 0
Shout my array at 1
Shout my array at 2
and the corresponding arrays.rock.out file:
foo
bar
baz
At this point, things get horribly crunchy, because the new syntax means the generated parser is now so slow that Mocha will not actually run this test. Which kinda sucks…
1) feature tests
../tests/fixtures/arrays
arrays.rock:
Error: Timeout of 2000ms exceeded. For async tests and hooks, ensure "done()" is called; if returning a Promise, ensure it resolves. (/Users/dylanbeattie/Projects/codewithrockstar.com/docs/rockstar/satriani/test/test.js)
at processImmediate (internal/timers.js:439:21)
So let’s get out our festive yak-shaving clippers and see how we can fix this up. First thing I did was to
paste the arrays.rock code into the online interpreter, and use Chrome’s JavaScript profiler to see what was taking so long.
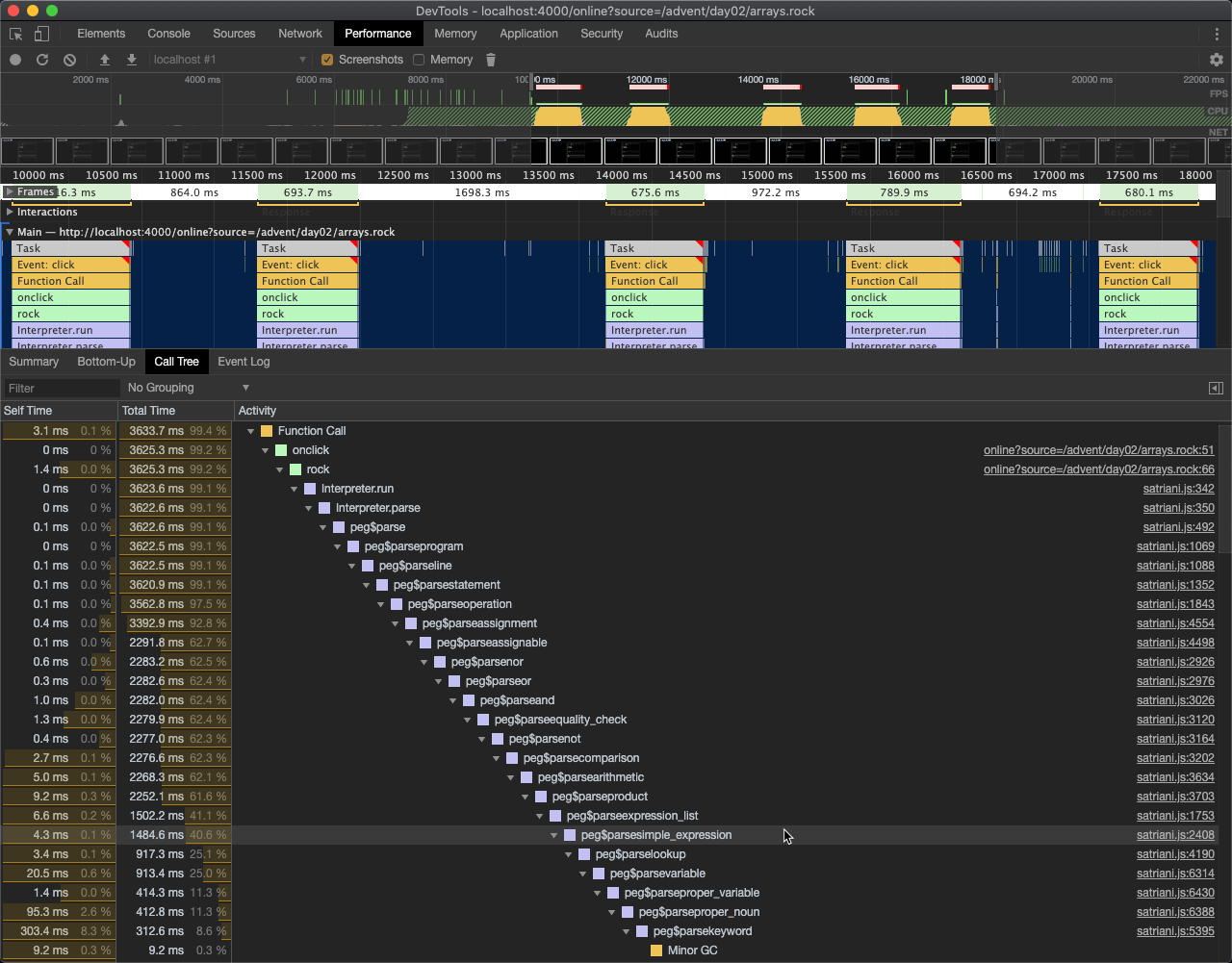
It took a bit of digging, but the smoking gun here is that peg$parsekeyword call right at the bottom
of the call stack. Just about any rule to do with parsing identifiers – variable names, array lookups,
function calls – involves a check to make sure you’re not using a reserved keyword as a variable name.
The grammar rules defining keywords look like this:
kw10 = 'mysterious'i
kw8 = ( 'stronger'i / 'continue'i)
kw7 = ( 'between'i / 'greater'i / 'nothing'i / 'nowhere'i / 'smaller'i / 'whisper'i / 'without'i)
kw6 = ( 'ain\'t'i / 'around'i / 'bigger'i / 'listen'i / 'nobody'i / 'return'i / 'scream'i / 'taking'i / 'weaker'i / 'higher'i
/ 'strong'i)
kw5 = ( 'break'i / 'build'i / 'empty'i / 'false'i / 'great'i / 'knock'i / 'lower'i / 'right'i / 'round'i / 'shout'i
/ 'small'i / 'take 'i / 'takes'i / 'times'i / 'until'i / 'while'i / 'wrong'i / 'minus'i)
kw4 = ( 'aint'i / 'back'i / 'down'i / 'else'i / 'give'i / 'gone'i / 'high'i / 'into'i / 'less'i / 'lies'i / 'null'i
/ 'plus'i / 'says'i / 'than'i / 'them'i / 'they'i / 'true'i / 'weak'i / 'were'i / 'your'i / 'over'i / 'with'i)
kw3 = ( 'and'i / 'big'i / 'her'i / 'him'i / 'hir'i / 'it 'i / 'low'i / 'nor'i / 'not'i / 'put'i / 'say'i / 'she'i
/ 'the'i / 'top'i / 'ver'i / 'was'i / 'xem'i / 'yes'i / 'zie'i / 'zir'i)
kw2 = ( 'an'i / 'as'i / 'he'i / 'if'i / 'is'i / 'it'i / 'my'i / 'no'i / 'of'i / 'ok'i / 'or'i / 'to'i / 'up'i / 've'i
/ 'xe'i / 'ze'i )
kw1 = 'a'i
keyword = (kw10 / kw8 / kw7 / kw6 / kw5 / kw5 / kw4 / kw3 / kw2 / kw1) !letter
So I went digging into the generated parser code and found this monster:
function peg$parsekeyword() {
var s0, s1, s2, s3;
s0 = peg$currPos;
s1 = peg$parsekw10();
if (s1 === peg$FAILED) {
s1 = peg$parsekw8();
if (s1 === peg$FAILED) {
s1 = peg$parsekw7();
if (s1 === peg$FAILED) {
s1 = peg$parsekw6();
if (s1 === peg$FAILED) {
s1 = peg$parsekw5();
if (s1 === peg$FAILED) {
s1 = peg$parsekw5();
if (s1 === peg$FAILED) {
s1 = peg$parsekw4();
if (s1 === peg$FAILED) {
s1 = peg$parsekw3();
if (s1 === peg$FAILED) {
s1 = peg$parsekw2();
if (s1 === peg$FAILED) {
s1 = peg$parsekw1();
}
}
}
}
}
}
}
}
}
Now, generated code generally isn’t too pretty, but that’s really, really bad in terms of
performance. All we actually need to do is check whether the identifier we’re looking at
is in a list of reserved keywords, and if it is, return false from the grammar rule that’s
trying to match it.
Stack Overflow to the rescue -
turns out PegJS supports predicates, which allow me to inline JavaScript function calls into the
generated parser code that controls whether particular rules will be considered a valid match or not.
So first I moved all the keywords into a constant JS array at the top of the rockstar.peg file:
{
const keywords = [
'mysterious', 'stronger', 'continue', 'between', 'greater', 'nothing', 'nowhere', 'smaller', 'whisper',
'without', 'ain\'t', 'around', 'bigger', 'listen', 'nobody', 'return', 'scream', 'taking', 'weaker',
'higher', 'strong', 'break', 'build', 'empty', 'false', 'great', 'knock', 'lower', 'right', 'round',
'shout', 'small', 'take', 'takes', 'times', 'until', 'while', 'wrong', 'minus', 'aint', 'back',
'down', 'else', 'give', 'gone', 'high', ',nto', 'less', 'lies', 'null', 'plus', 'says', 'than',
'them', 'they', 'true', 'weak', 'were', 'your', 'over', 'with', 'and', 'big', 'her', 'him',
'hir', ',t ', 'low', 'nor', 'not', 'put', 'say', 'she', 'the', 'top', 'ver', 'was', 'xem',
'yes', 'zie', 'zir', 'an', 'as', 'at', 'he', 'if', 'is', 'it', 'my', 'no', 'of', 'ok', 'or',
'to', 'up', 've', 'xe', 'ze', 'a'
];
function isKeyword(string) {
return (keywords.includes(string.toLowerCase()));
}
}
then modified the grammar rules for matching variable names (identifiers) like so – see
the !{ return isKeyword() } calls that are inlined into the grammar rules?
simple_variable = name:$(letter letter*) !{ return isKeyword(name) } { return name }
proper_noun = noun:$(uppercase_letter letter*) !{ return isKeyword(noun) } { return noun }
So. Added grammar rules for arrays. Created test cases. Discovered test cases were too slow to run using Mocha. Found out how to do JS performance tracing. Learned about predicates in pegjs. Improved parser performance. Merged improved parser code to the Rockstar master branch. Now, where were we again…?
Oh, yeah. Adding array support. So we can solve Advent of Code day 2.
So, here’s where we are. We can parse - but not yet interpret - this code:
Split the string into the array
Let the array at index be "foo"
Shout the array at index
and that gives us a valid parse tree:
{
"list": [
{
"split": {
"array": { "lookup": { "variable": "the_string" } },
"target": { "variable": "the_array" }
}
},
{
"assign": {
"target": {
"variable": "the_array",
"index": { "lookup": { "variable": "the_index" } }
},
"expression": { "string": "foo" }
}
},
{
"output": {
"lookup": {
"variable": "the_array",
"index": { "lookup": { "variable": "the_index" } }
}
}
}
]
}
Next step is to implement support for doing lookup and assignment with support for indexed variables.
I’ve isolated these parts of the main interpreter loop into their own functions. Some things to note here:
- The array index can also be an expression, so needs to be evaluated in the current environment before we can use it
- Array lookup and assignment both allow pronoun aliases, so we need to dealias the identifier in the expression
- The actual job of assigning and retrieving values is delegated to
env.lookupandenv.assign
function lookup(expr, env) {
let lookup_name = env.dealias(expr);
let index = evaluate(expr.index);
return env.lookup(lookup_name, index);
}
function assign(expr,env) {
let alias = "";
let value = evaluate(expr.expression, env);
let target = expr.target;
let index = evaluate(target.index, env);
if (target.variable.pronoun) {
alias = env.pronoun_alias;
} else {
alias = target.variable;
env.pronoun_alias = alias;
}
env.assign(alias, value, index);
return value;
}
And the actual implementation in the Environment class:
Environment.prototype = {
lookup: function (name, index) {
if (name in this.vars) {
if (typeof(index) != 'undefined') return this.vars[name][index];
return this.vars[name];
}
throw new Error("Undefined variable " + name);
},
assign: function (name, value, index) {
if (typeof(index) != 'undefined') {
if (! (name in this.vars)) this.vars[name] = {};
return this.vars[name][index] = value;
} else {
return this.vars[name] = value;
}
},
And voila! we now have support for reading and writing arrays using the new at keyword.
Finally, support for the new split operation. Now here, I have to make a decision.
Split the string into the array
If you don’t specify a delimiter, what happens? Should we use a default (and if so, should it be space? Comma? Tab?) Should we do nothing? (No, because it’s a bit pointless).
So here’s what I want to implement:
Split "a,b,c" into the array (the array is ["a", ",", "b", ",", "c"])
Split "a,b,c" with "," into the array (the array is ["a", "b", "c"])
Cut your cake with my knife into pieces
Except - with is a reserved keyword in Rockstar, used for addition.
So I have to make another decision:
Option 1: Use another keyword
Split "a,b,c" using "," into the array
Cut your cake using my knife
Option 2: Don’t allow operations in this context
The proposed syntax is only a problem if I allow, for example:
Split "a,b," with "c,d," into the array
- this then becomes ambiguous – do we mean ‘split “a,b,” using “c,d” as the delimiter’, or do we mean ‘add “a,b,” to “c,d,” and then split it?’
Option 3: different syntax
Alternatively, I move the delimiter to the end of the operation
Split "a,b,c" into the array (the array is ["a", ",", "b", ",", "c"])
Split "a,b,c" into the array with "," (the array is ["a", "b", "c"])
Cut your cake into pieces with my knife
This also means that, potentially, both the delimiter and the target expression
could be optional, so that cut my life into pieces and cut your cake with my
knife are both valid Rockstar expressions. cut with no target variable specified
will modify the source variable in-place; cut with no delimiter specified will
split a string into an array of individual characters.
Finalising Syntax
So here’s what I’m actually going to implement:
- Keyword
cut, with aliasessplitandshatter - Optional delimiter - if omitted, split strings into individual characters
- Optional target variable - if omitted, it’ll modify the variable in-place.
Split "a,b,c" into the array (the array is ["a", ",", "b", ",", "c"])
Split "a,b,c" into the array with "," (the array is ["a", "b", "c"])
Split my string (my string will split in-place to an array of characters)
Split my string with x (split my string in-place using the current value of x as a delimiter)
The grammar rules for supporting these four cases are:
split = 'cut'i / 'split'i / 'shatter'i
string_split
= split _ s:assignable _ 'with'i _ d:expression
{ return { assign: { target: s, expression: { split: { source: { lookup: s }, delimiter: d } } } } ; }
/ split _ s:expression t:into_target _ 'with'i _ d:expression
{ return { assign: { target: t, expression: { split: { source: s, delimiter: d } } } } ; }
/ split _ s:expression t:into_target
{ return { assign: { target: t, expression: { split: { source: s } } } } ; }
/ split _ s:assignable
{ return { assign: { target: s, expression: { split: { source: { lookup: s } } } } } ; }
and because we’re using the parser to treat splits as a special case of assignment, the only thing we need to add to the interpreter is the actual splitting behaviour itself – evaluate the source expression and the delimiter expression, do the actual split to get the array result, and then return that to the interpreter, which will handle the subsequent assignment.
function split(expr, env) {
let source = evaluate(expr.source, env);
let delimiter = evaluate(expr.delimiter, env) || "";
return source.toString().split(delimiter);
}
And… we’re pretty much done. Now, what was that advent of code day 2 thing again? :)